scrapy教程
scrapy设置随机代理IP地址
通常我们使用scrapy的时候,需要使用代理IP,本文介绍scrapy设置随机代理IP地址。
首先,我们需要再settings.py里面写入代理IP列表,如下代码:
PROXIES = [ 'http://username1:password1@ip1:端口1', 'http://username2:password1@ip2:端口2', 'http://username3:password1@ip3:端口3', 'http://username4:password1@ip4:端口4', 'http://username5:password1@ip5:端口5', 'http://username6:password1@ip6:端口6', ]
然后再middlewares.py新增如下代码:
class ProxyMiddleware(object):
def __init__(self, ip):
self.ip = ip
@classmethod
def from_crawler(cls, crawler):
return cls(ip=crawler.settings.get('PROXIES'))
def process_request(self, request, spider):
ip = random.choice(self.ip)
request.meta['proxy'] = ip最后在settings.py里面加入如下代码:
DOWNLOADER_MIDDLEWARES = {
'kyqb.middlewares.ProxyMiddleware': 300,
}这样就完成了,下面我们来测试代理IP是否成功。
新建一个爬虫testip.py,写入如下代码:
import scrapy
class Spider(scrapy.Spider):
name = 'ip'
allowed_domains = []
def start_requests(self):
url = 'https://www.ipip.net/'
for i in range(4):
yield scrapy.Request(url=url, callback=self.parse, dont_filter=True)
def parse(self,response):
ip = response.xpath('//ul[@class="inner"]/li[1]/a/text()').extract_first()
print(ip)执行:scrapy crawl ip,如果获取的是不同的且是你的代理IP列表里面的,那说明就成功了,如下图:
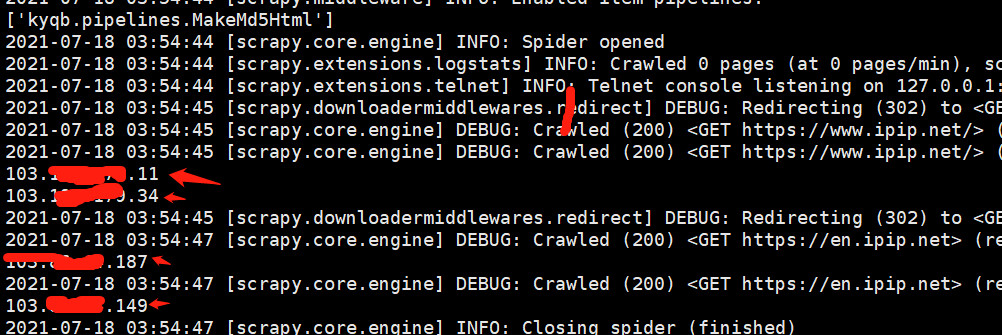
如上图,scrapy设置随机代理IP地址就成功了。
最后修改:2021-07-18 03:46:05